Base, Instruct, and Think LLMs: What's the Difference?
When I was trying to learn more about LLMs, I found terms like pre-training, post-training, base model, instruction following, and reasoning really confusing. I didn’t understand what a base model was or why it needed post-training.
In this article, I aim to help readers build an intuitive understanding of base models, instruction-tuned models, and thinking models through several practical examples. I won’t go into detail about how post-training works - there are already plenty of articles and surveys that cover available methods. You can think of post-training as a collection of techniques and practices designed to shape specific behaviors.
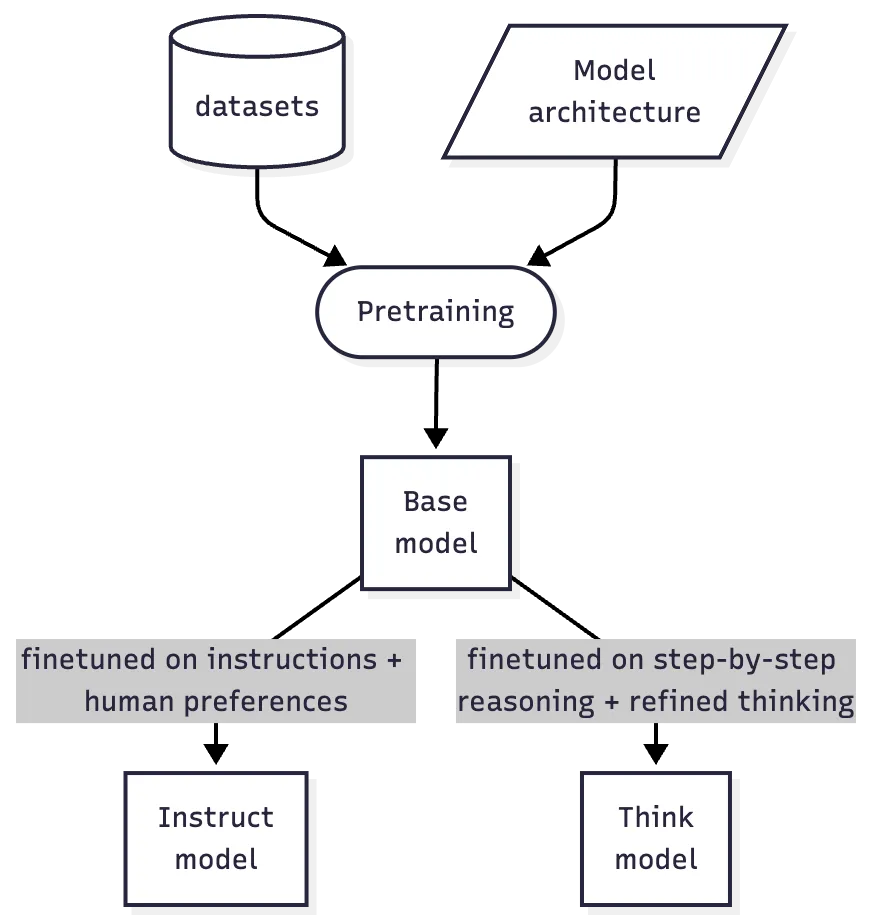
The simplest mental model I recommend is shown in the image. While it's not completely accurate, IMHO it's a good enough approximation for a high-level overview.
AllenAI
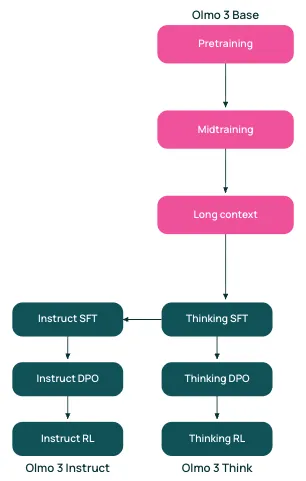
I’ve really enjoy following AllenAI’s work, as they’re the only company I know of that openly shares nearly everything they build and use. The release of Olmo 3 is what inspired me to write this article. So, without further delay, let’s start with a more detailed visualization from AllenAI release note of the mental model I mentioned earlier.
Base Model
Everything starts with a "base" (or "foundation") model. For example, Olmo 3-Base is the foundation model developed through three stages of pretraining: general knowledge (6T tokens), reasoning enhancement (100B tokens), and long-context extension (100B tokens). However, this isn't a one-size-fits-all approach - different companies may use a different number of stages and data mixes to create their base models. This costly process, requiring massive compute that few organizations can afford.
Now, let’s take a closer look at how it works.
Instruct & Think
As you can see from the "Base Model" section, the model is capable of generating highly plausible text, but we're used to seeing very different behavior: we're used to having it answer our questions in the chat interface, with or without long reasoning chains. So how can we move from text completion to something more practical?
The answer is supervised fine-tuning, direct preference optimization! I promised a simple and fast way to build intuition. Let me explain both in simple terms.
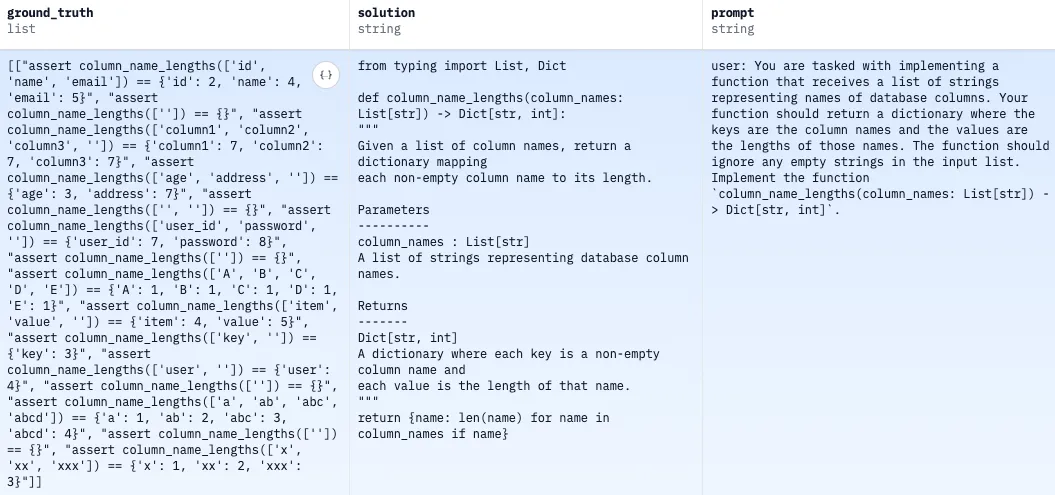
Supervised Fine-Tuning (SFT) is a method used to adapt pre-trained ("base") language models to specific tasks by training them on labeled, task-specific datasets. If you look closely, you'll see that the datasets used for thinking SFT are quite limited and highly focused. For instance, both are structured as user-assistant interactions. The thinking SFT dataset includes a "think" phase, whereas the instruction-following dataset consists only of request-response pairs. By the way, it also includes examples of function calls!
Here’s a single training example for instruction-following supervised fine-tuning (SFT):
[
{
"content": "Write a program that reads a single line of input containing a string s. ... <truncated>",
"function_calls": null,
"functions": null,
"role": "user"
},
{
"content": "s = input()\nclean = ''.join(c.lower() for c in s if c.isalnum())\nprint(clean == clean[::-1])",
"function_calls": null,
"functions": null,
"role": "assistant"
}
]
Here’s a training example that includes the <think> phase:
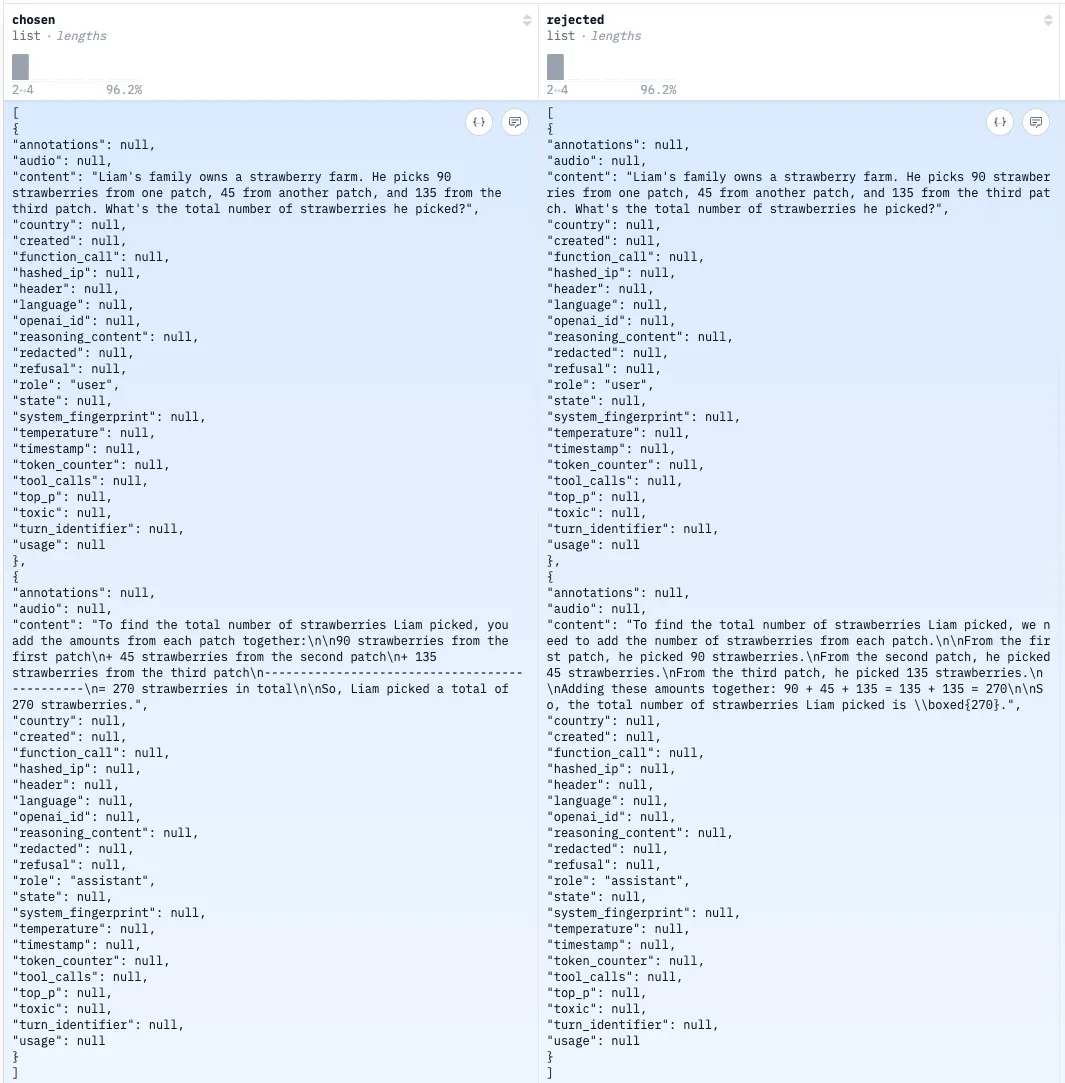
Direct preference optimization is just what it sounds like: we provide examples of preferred and rejected outcomes for a given prompt. This process helps align the model with specific preferences - any preferences, in fact. Here is a training example:
I'm not going to provide a notebook for these two stages of model specialization. However, it's a simple task and can be easily adapted from the notebook above if you'd like to give it a try.
Before we ship thinking and instruction-following versions of a model, we need to do the very last thing: Reinforcement Learning with Verifiable Rewards. RLVR is RL training where the reward signal can be objectively verified rather than relying on human judgment. There are many categories of problems like this: math, physics, coding, etc. The answer is clear, verifiable, and does not require human judgment. Complex name, simple concept. Here is a training sample example:
Once again, the code adaptation is straightforward, so let's skip it for now and call it a day! 🎯